
randy's Recent Posts

Klauss! <3
Happy to hear you got it working.
I'm very glad to hear this, thanks for the update!
You could be on an HTTPS connection that your browser thinks is insecure. It's fine, just choose "download anyway" however your browser allows. Maybe right click will access this.
Hi, that's a good question! The issue is that Sumu has 64 partials in each patch cord. And 8 voices. So it's unclear how to display up to 512 signals in a dial in a useful way! Maybe the average of the partials, or maybe high or low, or maybe just the most recent voice? There might be a couple of useful modes but this is definitely something to experiment with at length so in Sumu there's still no in-dial display.
In Aalto 2 etc. I'll definitely keep the displays.
In the previous newsletter I sent out a customer survey for the first time ever.
Thanks to everyone who took the time to respond. I was truly overwhelmed with the amount and the positivity of your feedback. This work can be isolating sometimes when I'm typing away here in my half-basement and thinking about new sounds and new UIs, so let me get a little mushy on you and say from deep in my feels: your kind messages gave me more certainty that I'm doing the right stuff, and more energy to continue on the path.
I have some tangible results to share that might be of interest to you too, so let's dive in!
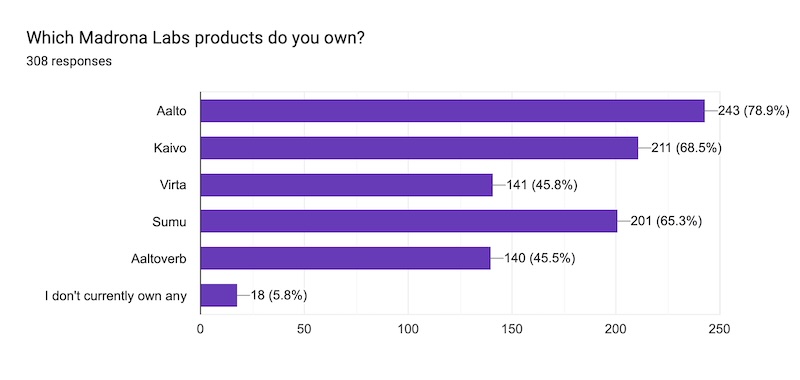
Aalto being our most popular synth jibes with what I've been seeing over the years. It's something special and I'll work to keep it that way. Kaivo and then the new Sumu come after that, and Virta and Aaltoverb a ways down. again, no surprises.
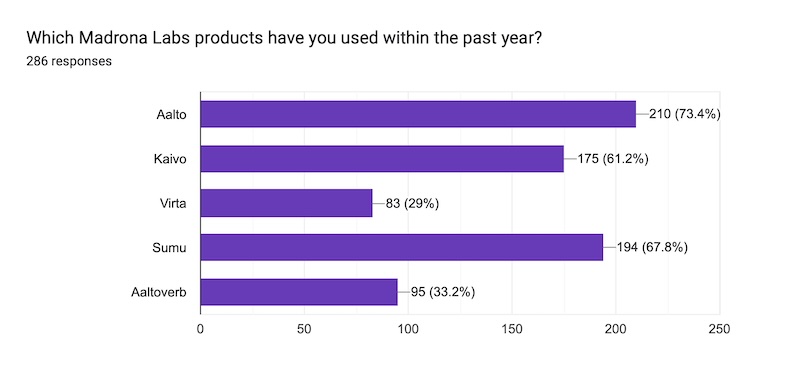
This is cool because along with the first question it gives us a (bought / used it recently) ratio, which is the best quantative measure I can think of for “did I make something useful?” Aalto here is a perennial favorite, and Sumu leads the pack—though that's skewed of course because it has not been out for that long. Virta is looking the saddest and that gives me some ideas for how to make it more accessible. Honestly I think the “it's a synth, it's an effect too!” approach makes it a bit confusing. That’s something I can work on.
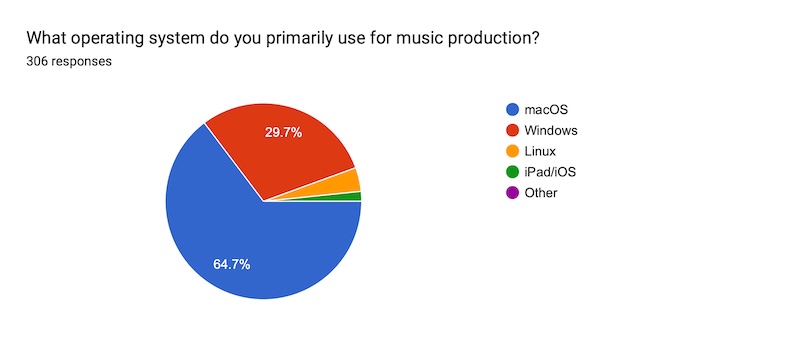
Let the OS wars begin! (seriously tho, ack, no no no let's not.) Um, I work hard to make good interfaces that are sometimes opinionated and design-forward, and it makes sense this would connect with a Mac crowd. Windows is well-represented though, and definitely not a second-class citizen here. Honestly given the missteps made by both Apple and Microsoft in software over the last year (UI eye candy nobody wants, forcing adware and AI slop on us, ignoring fundamental usability problems), both companies are on my shit-list right now. So to that 4% of Linux folks, I completely get it and we're making slow but real moves in your direction.
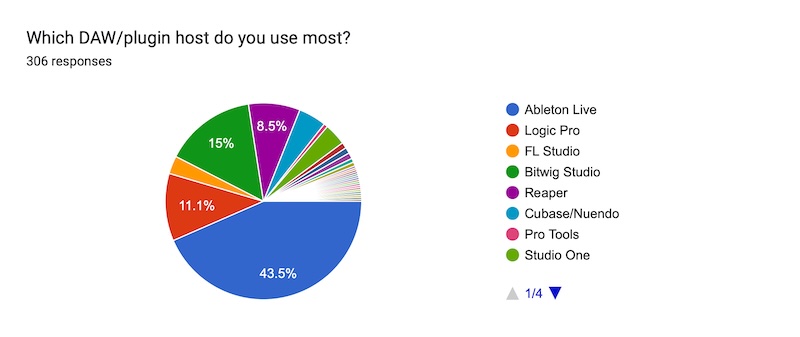
Ableton Live? Never heard of it, I'll have to try that one someday. Just kidding, it's my daily driver and it's no surprise that's true for a lot of you as well. Bitwig beating out Logic for second place is a bit of a surprise. I'm happy to see our affordable weird cousin Reaper rounding out the top 4.
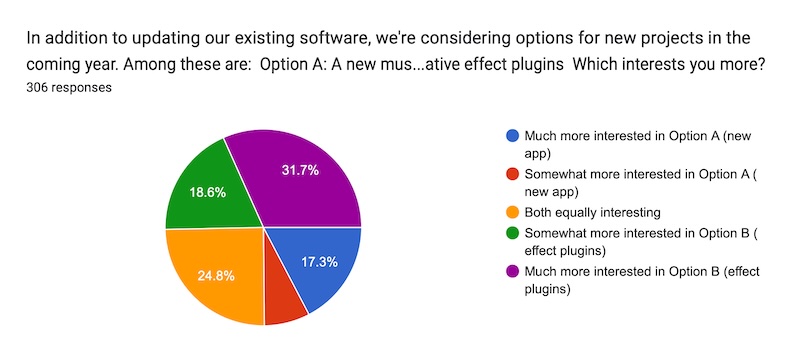
This was interesting. Combined interest in new effect plugins is about twice that of interest in a new app. Now that doesn't mean we will take one course and not the other. (¿Por qué no los dos?) There are good reasons for making an app even if it's only the top pick of 25% of our customers. But honestly I guessed these numbers would be the other way around. Amazing what you learn when you ask people!
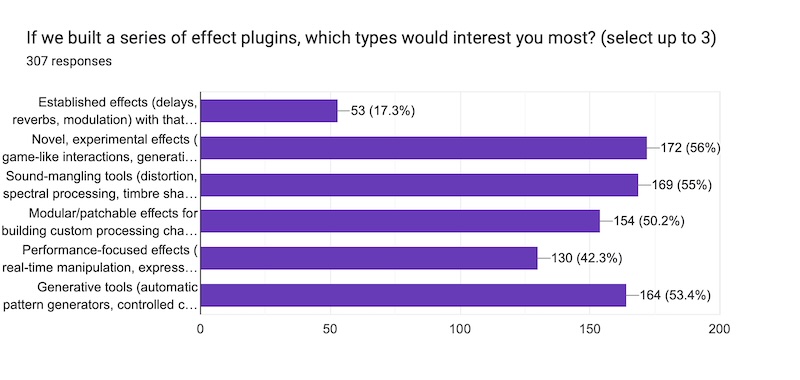
As far as the quantitative data go, this one makes me feel good about letting our freak flag fly. Sorry about the formatting here, but you can get the idea. Novel, experimental effects are in the lead, followed closely by other kinds of tools that could frankly also be in the novel/experimental category. What there's not much interest in is "Established effects with that Madrona Labs sauce." I love all the software bebs, including Aaltoverb, but my understanding now is that we should keep fishing for ideas deeper down in the ocean of new and different sounds. It's kind of what we do, and I'm happy to see it's why you're here.
Sumu 1.3.0 is now available for download! This release fixes some bugs and adds workflow improvements including partials import feedback.
Changes include:
- fixed noise in pulses to be different per voice
- fixed possible crash with very small partials maps
- fixed Vutu partials import on Windows
- added partials import progress bar
- partials import dialog remembers start directory
- added diagnostics and log for partials import
- patch save remembers start directory
- fix stuck notes when host buffer size < 64
When attempting to import a Vutu partials file with more than 64 partials, Sumu now fails and logs the result to an output file instead of producing a partials map that can't be played correctly.
Thanks to our beta testers, and to everyone who sent in feedback. Enjoy the sounds!
Wow, I haven't even shipped a Windows ARM version so that's kind of amazing. I guess it means their translation is working well. Thanks for letting me know!
I'm beta testing a fix for this now!
I've heard some other reports of missing or stuck notes with Sumu. Sorry for the inconvenience.
What buffer size are you using in FL? Another person who ran into this issue was able to work around is by increasing the buffer size from 32 to something over 64.
In any case I'll try to find a fix for this soon.
@bastiaan This is useful info, thanks. I'll continue to work with people running into this problem on Windows and hopefully find a fix soon.
@intervolver I hope this has been fixed in the 1.2.0 update.
@tomi I see you are on Windows. I wonder if there could be an issue with permissions. If the DAW or Sumu does not have permission to write files, that could be a problem. You could temporarily try running your DAW in Administrator mode as a test. If this solves the issue, then you can probably fix it by changing some Windows permission settings.
This year it seems desirable and possible for Madrona Labs to make a Soundplane to CV device. This would be primarily a Eurorack module, but the circuit could also be built into its own enclosure for use with vintage synths etc.
Normally I do most of my design work in private, and only announce a product when it's pretty much done. But we (Brian and I) are going to change it up this time. Because neither of us is that deeply into the Eurorack world, it makes sense to solicit input early on in the process this time. This is going to be a utility device (though hopefully an elegant one) — so before we get too far along, let's make sure it will be useful to you!
The basic idea
USB jack for powering the Soundplane. Module puts out CV / gates / mod outputs for individual touches. Like the Soundplane app, a zone map decides how the Soundplane surface is divided up into notes and what those notes are. You can switch between zone maps, and the name of the current one should be displayed somehow. Aside from this, visual feedback will be at least an LED per Z value. To keep costs low, probably nothing too graphical or fancy.
We're looking for input on things like:
How many voices?
Each voice of touch output will probably have 4 outputs for pitch, x, y and z. Setting up many voices on a modular is not the way most people use them, so I'm guessing that two voices of output will take care of 90% of what people want. We would probably add an expander module for more voices.
Any interesting modes?
A switch that changes z (pressure) into a strict on/off gate might be useful. Any other things like this?
Layout?
individual voice groups vertical or horizontal? voice outputs at bottom or top? I'm thinking top, because a USB jack on the bottom will go to the Soundplane.
Power?
The module will need roughly 250mA at 5v to power the Soundplane. Brian will correct me if I'm wrong. Then there's whatever computing and display the module needs to do, and the outputs. Do we need our own power supply, or a list of compatible Euro power supplies that we can point people to? Any choices in connectivity to make here?
Finally, we're still looking for a great name…
Analyzing a sound with Vutu to make a partials map is a complicated process. While some sounds open up right away, it can be hard to find the combination of control settings that reproduces your sound in 64 partials or fewer.
I have one video I made about the topic a long time ago, but I've never found the time to write up a good guide.
Enter Sumu user @pete12000, who uploaded the transcript of my video and the manual into ChatGPT. It generated this summary that I think is a good general-purpose recipe for analyzing a sound. Thanks Pete!
The Six Knobs: Balancing Sound Quality vs. Staying Under 64 Partials
1) Resolution (Hz)
What it controls: The minimum spacing (in Hz) between any two partials in the output.
What you'll hear/see when changing it:
- Higher resolution value (bigger spacing) → fewer partials → easier to stay under 64, but it gets "bloopy and synthetic" fast.
- Lower value (tighter spacing) → more faithful (more partials captured) → you can blow past 64 if you're not careful.
Use it like this: Treat Resolution as a last-mile partial-count reducer after you've done smarter filtering with High/Low cut and Amp floor.
2) Window Width
What it controls: Turning it up "increases the resolution in time" of each sample.
What you'll hear/see:
- Often, higher window width = more convincing playback ("great fidelity") for that sample.
- But if window width is high, you can generate "peaky sounds" that can start to sound noisy, especially depending on Frequency drift.
Use it like this: Window width is a quality knob first (time/detail), but it can create analysis behavior that you then tame with Frequency drift.
3) High Cut
What it controls: The highest frequencies that will be reproduced (i.e., you're telling the analysis/export to ignore content above this cutoff).
Why it matters for the 64 limit: This is one of your best "free" ways to drop partial count. In the video, turning High cut way down makes the sound simpler and he points out it may take only 13 partials to play back.
Use it like this:
- Lower High cut until you just start to feel you're losing important brightness/detail, then bump it back up a bit.
- Especially effective on noisy, bright recordings where the top end would otherwise "spend" lots of partials.
4) Amp Floor (dB threshold)
What it controls: How quiet the source can be before it gets captured into a partial.
What you'll hear/see:
- Raise Amp floor → strips quiet detail → fewer partials active → often still "very intelligible," and can drop playback partials a lot.
- Lower Amp floor a lot (e.g., very negative) → "all the noise from the original file is being turned into partials." That can sound cool, but it burns your partial budget quickly.
Use it like this: This is your main anti-noise / anti-hiss control for staying under 64 without wrecking tone.
5) Low Cut
What it controls: Strips out the low frequencies (a low-frequency cutoff).
What you'll hear: He calls out the "telephone effect" when you push it up.
Use it like this:
- Use Low cut to remove rumble, mic handling noise, HVAC, proximity boom, etc.
- If the sample's "identity" lives in mids/highs (voice snippets, many found sounds), Low cut can reduce wasted partials while improving clarity.
6) Frequency Drift
What it controls: How quickly partials are allowed to move in frequency.
What you'll hear/see:
- With drift high, partials can move very quickly; with some settings (notably high Window width) that can contribute to a noisy character ("noisy fast motion in the partials").
- With drift lower, quickly-changing traces are removed, so it won't play back those rapid movements, which can smooth out the analysis.
Use it like this: Drift is your "stability/smoothing" knob:
- If the resynthesis feels jittery, fizzy, or overly busy → lower drift to suppress the fast-moving stuff.
- If your source genuinely has expressive pitch motion you want to keep → allow more drift (but watch Max active).
The Workflow: Fast Way to Stay Under 64 Without Trashing Fidelity
-
Reanalyze, then read the printout — especially Max active.
- If Max active > 64, you can't export a Sumu-friendly result.
-
Do the "cheap wins" first (usually best quality-per-partial):
- High cut down to remove expensive top-end clutter.
- Low cut up to remove rumble/boom you don't need.
- Amp floor up until noise stops becoming partials.
-
Then tune for fidelity:
- Adjust Window width for the most convincing playback.
-
Only then use Resolution as the blunt instrument:
- Nudge Resolution upward only enough to get Max active under 64 (because too high gets "bloopy/synthetic").
-
If the result is peaky/noisy/jittery:
- Lower Frequency drift to remove fast-changing traces and smooth playback.
Since Sumu 1.1.3 was released with some important bug fixes, I've been working on optimization. The release notes just say "- many optimizations to app framework and DSP" but I know some of you will be interested in a deeper dive. This is written for people who are interested in programming. So while I'm not assuming a great amount of specialized info, I'll throw around terms like "compile time" and "runtime." If you want to know what anything means, you can ask a search engine or even me, in the comments! Let's dig in.
With the 1.1.3 version released October 1, I made an eight-voice patch that uses the filter and automatically makes sound, as my rough benchmark. I also set up a document in the app i use for much of my testing, the AudioPluginHost that comes with JUCE. I use this because it launches so fast, just a few seconds compared with maybe 20 seconds for the major DAWs. When looking at the Activity Monitor in MacOS, the CPU usage for my AudioPluginHost doc was 63%, plus or minus 0.5%. A rough number but good enough to see the big changes I'm making now, and when I don't need precision, I usually do what's quickest!
This 63% measures against one CPU core, of which most of our machines have around 8. Still, very very heavy CPU use for a softsynth. Let's do something about it. Using Apple's Time Profiler developer tool, I made a list of the biggest CPU time users in the code. While Activity Monitor is precise enough to check that I'm making forward progress, I use the profiler to identify which parts of the code are the hotspots. Let's save some cycles!
Optimization 1, hashed symbol rewrite in madronalib
My plugin framework has a lot of code based on an internal Symbol table. It's nice to write stuff like parameters["osc1/gain"] instead of parameters[kOsc1GainParamIndex] because then you have to make the list of those index constants somewhere and keep it up to date. A possible downside of indexing everything with Symbols is that you can only catch spelling errors at runtime, not compile time. But for me it's faster to bang out code this way and I love brevity, so it's a good tradeoff.
Version 1 of this Symbol code has an implementation where Symbols were stored by index, in order of their creation. Since this can't be done at compile-time, some work is needed at runtime to turn the string "osc1/gain" into a symbol index every time you want to access something by a symbol. I realized later that many of these lookups could be at compile-time instead (or in C++ terms, constexpr) if I used a hashing function to generate the index. Using a 64-bit index means that hash collisions are astronomically unlikely. Also, the debug version of the software checks for collisions so if that very unlikely thing happened someone could rename a variable.
We still want to index some things by un-hashed Paths, File trees for example. And there's a need to make Symbols on the fly sometimes, as when reading in config files. So after rewriting my classes SymbolTable and Symbol, I had my Path class to rewrite, with a GenericPath class that can be used to implement container classes like Tree, and Path and TextPath subclasses for the different use cases. It was a lot to think about. But in a couple of weeks of working on this part time I had my much-improved replacement code for this fundamental part of my framework.
speedup: 63% -> 60%
Optimization 2, removed mostly unused i/o scale multiplies in Patcher
I had designed some flexibility into the DSP object that implements Sumu's central patch bay, in the form of individual scales for each input and output. It turned out that in the final design, most of these were set to 1.0 most of the time, so it was quicker to just multiply the few inputs and outputs that needed different values, as special cases. Of course multiplying things takes time so we like to avoid it.
speedup: 60% -> 54%
Optimization 3, don't send published signals when there is no view
In order from signals to get from the DSP core to Sumu's GUI, for meters and displays, the concept of publishing is used. Sumu publishes signals and the GUI subscribes to them. I noticed that the code was doing some of the work for this publishing even when there was no window showing. Turning all the published signals code off when there's no window was an obvious time-saver.
speedup: 54% -> 47%
Optimization 4: optimized LadderFilter integration to reduce number of operations
One of the more expensive DSP components in Sumu is its nonlinear resonant Moog-style ladder filter. This is derived from work by D'Angelo and Välimäki. I love the onset of resonance in this filter model, the way it starts to oscillate just a bit in a way that depends on the input signal. It has a real liveness and sounds very full and clear.
The filter is four nonlinear stages with a feedback stage. I stared at my naive implementation, did some simple math and realized that by juggling the variables I could change the scaling of the signals running through the filter by a constant amount, and thereby save a multiply per stage. High school algebra for the win!
speedup: 47% -> 45%
Optimization 5: LadderFilter() 4x object
Because of its four stages, the Moog filter model is a bit slow: each stage depends on the result of the previous stage, and the values must be calculated one after another for each sample of audio. If we consider one of these filters by itself, SIMD (SSE / AVX / NEON) is not immediately helpful, because while SIMD can do four multiples at once, the values can't depend on each other.
Where SIMD does help us out is in running four or more of the filters at once. By changing the filter code to operate on groups of four samples rather than single samples, we can make a 4x filter bank that runs in only a little more time than the single filter. Because the inputs and outputs are arranged [a1, b1, c1, d1], [a2, b2, c2, d2], ... in memory, we can think of these as vertical filter banks, operating on four columns of signal in contrast to the horizontal single filter.
Sumu has two of the filters in each voice, applied to the left and right outputs. So if we have more than two voices of Sumu, we need to calculate four or more filters anyway. When we have eight whole voices and 16 filters, the savings are big, around 10% of our remaning total CPU!
speedup: 45% -> 41%
Optimization 6: - try tanhApprox w/ div approx in LadderFilter
The nonlinearity in each stage of the filter is implemented using a tanh (hyperbolic tangent). This is expensive operation, so we make do with an approximation. Picking a good one is as much art as science, because in the context of the filter different approximations will give different sounds. For the single filter I had already picked an approximation based on a simple ratio of polynomials: y = x(27 + x^2)/(27 + 9x^2). Though a deep understanding why this simple product is such a good match for our transcendental function eludes me, as we've established I'm good at simple math and timing things.
We were already using the above approximation in our single horizontal filter. With SIMD in the mix, though, there's an appealing idea in the form of the SSE function _mm_rcp_ps. Divides are one of the most CPU-intensive operations, and our approximation unavoidably contains one. But _mm_rcp_ps is a reciprocal approximation with the potential to run much faster than the full divide. It uses a lookup table implementation internally to produce a roughly 8-bit accurate result in around half the time of the more accurate division.
Now when you introduce any approximation, there are going to be changes in the output, possibly audible. This did not apply to the 1x -> 4x filter bank changes because the SIMD values are all still full-precision 32-bit floating point. But the divide approximation would change the feedback path of the filter to have less resolution. It might not sound different, but it might. Fortunately, this was a very quick change to try out.
And the somewhat surprising result: it wasn't any faster! This isn't too hard to explain: along with the reciprocal estimate, you still have to do a multiply to get the divide estimate. And, even though we are doing four filters at one, each stage still has data dependencies. I haven't used a timing simulator to do a deep dive into this (godbolt.org is the one I would try) but my guess is that the expensive divisions all fit into time that was spent in each stage waiting for previous values anyway. So the result:
speedup: none
So in around ten weeks we've gone from using 63% of our CPU for eight voices to 41%. This is around a 35% speedup, and IMO the difference between "what are they smoking" and U-He Diva territory. And, it's only the start! More optimizations remain. But now is a good time to make a release and share this work. It's there for you in Sumu 1.2.0. Enjoy the sounds!
Glad to hear it's working out. More optimizations to come!
*** updated with latest Mac and Windows links ***
I've just posted a public beta of Vutu for MacOS (edit: and now for WIndows!). Vutu is the sound analysis program for the upcoming Sumu synthesizer.
links:
Mac: http://madronalabs.com/media/vutu/Vutu%200.9.9.dmg
Windows: http://madronalabs.com/media/vutu/VutuWin0.9.10.zip
A Vutu quickstart video is also online now. I haven't had a chance to write any better documentation yet, and I"m not sure I will before I get the Sumu beta out. However, Vutu in its current form is pretty simple anyway, and most of what you need to know you can find out by fooling around with the dials and listening and looking.
Vutu analyzes sounds using Loris, developed by Kelly Fitz and Lippold Haken at the CERL Sound Group. A detailed intro to Loris is available on Hakenaudio.com: Current Research in Real-time Sound Morphing More publications are also linked from the CERL Sound Group Loris page. Loris is distributed under the GNU General Public License (GPL) and thus, Vutu is also. Vutu's source is available on Github.
Vutu is built on a cross-platform GUI framework I developed called mlvg. Compiling it for Windows and Linux should therefore be a reasonably easy task, but I know there will be a bunch of details to iron out, so I'm not taking that on until after I can make a Sumu beta.
That was a lot of info and links. Why would you want to play with Vutu right now? Some reasons might be:
- You want to get started making your own sound bank for Sumu.
- You have to try out the newest audio software, whatever it is, and this was just released today.
- You enjoy looking at bandwidth-enhanced partials and hearing odd noises.
Each voice of Sumu will be able to play back 64 bandwidth-enhanced partials simultaneously. A bandwidth-enhanced partial is basically a single sine wave, modulated with noise. So at any given instant of time, in addition to frequency, amplitude and phase, it also has a bandwidth, or noisiness. Making sounds out of such partials is a very powerful technique, and I think it's pretty easy to grasp. What's been difficult about additive synthesis is the large amount of control data that's needed. How do you generate it all? My answer in Sumu is to use the familiar patchable interface, but extended so that each patch cord carries separate signals for each partial. This allows sound design in a playful, exploratory way that should be familiar to any modular user. Honestly I think it will be fun as hell.
Thanks to Kelly Fitz and Lippold Haken for creating and sharing Loris. Thanks also to Greg Wuller for helping me get going with the Loris source code, and for utu, which became Vutu. Utu is a Finnish word for "mist" or "fog", like Sumu. Vutu is short for visual utu.
Vutu requirements
A Metal-capable Mac running MacOS 10.14 (Mojave) or greater.
Vutu is native for Intel and Apple Silicon.
Since it's an analyzer and not a real-time program (except for playing the results), CPU doesn't really matter.
Thanks for sharing! With a patch that uses the filter, you should see more of a difference.
Hi @marsdietz thanks for your kind note. I hear your compelling use case for an iOS version. I'm not working on iOS versions just yet, but I'm working on things that we would need to get in place before that effort. in other words you'll see Aalto 2.0 before too long, and shortly after that it could be possible to have an iOS version. I'll probably telegraph my intent before that and solicit some beta testing. Please stay tuned!
Happy Solstice, and here's to change and evolution. This goes out with all my best wishes to everyone for health, peace and prosperity in what has been such a hard year for so many. I hope that, despite COVID, you are finding ways to keep sane and happy, to nurture your body and spirit. A few weeks ago I got away on a short trip to meet some friends at the Pacific Bonsai Museum. That's where the lovely grouping of golden larch trees on the sale image here comes from. Visiting was a meditative, inspiring and world-expanding trip for me and if you're in the Seattle area, I recommend it highly.
From now through January 6 2021, our year-end sale is happening! You can use the code EVOLVE to get 30% off all our software. If you're an Aalto fan but you've been holding out on getting Kaivo or Virta or Aaltoverb, now's a great time. And yes, our simple bundle deal is in effect along with the year-end discount, if you choose to take advantage of them both. This results in some big discounts!
Finally, if you're looking for a last-minute gift, you should know that it's easy to give a Madrona Labs software license! A gift license can even be part of a simple bundle with one you bought for yourself and I'll be happy to transfer it free of charge (and judgement). Just email me at support@madronalabs.com to let me know. I'm taking Dec 25, Dec 31, and Jan 1 away from the computer but otherwise I'll be available within 24 hours (and probably less) to help make your holiday dreams come true.
Yep, we're about to have our end of year sale in a couple of days!
There's no further discount on the Studio Bundle however. We cap discounts at 30% to keep things sane and that's what the bundle offers any time.
I'm working to grow the company to where we can make a Soundplane Model B and support it well. it's been a long journey! Thanks for your continued interest.
I'm starting Team Notes as a place for me and other folks on Team Madrona Labs to post more casual things for a smaller audience. If you're seeing this, I guess you're that audience. Welcome!
Typical posts might be special interests within our special interest: technical details about making the software, or about making the coffee, what we're listening to, rants on technology and how it's making everything better or making everything worse, recipes... you get the idea. If there's anything you've always wanted to know, please reply here with your ideas!
This orange clipboard has my notes from the current Sumu optimization. I'm figuring out how to run four of the Moog filters in parallel in around the time it previously took to run one, and thinking about how to generalize this solution in an elegant way. I still do big abstract thinking much better when I'm using actual pen and paper.
Making code faster with SIMD (Single Instruction, Multiple Data) processing is something I've enjoyed doing since Motorola first released their Altivec-enabled PowerPC processors. From Altivec to SSE and AVX and ARM NEON, the SIMD concept has remained largely the same across processor generations for the last 25 years. Compilers have gotten better at optimizing C++ code for SIMD, but to get the fastest results, the right algorithms and data structures have to be picked to kind of make the CPU happy, which is much higher-level thinking. And zooming out even further there are more human-centered tradeoffs to think of: what kind of code reduces the potential for bugs, what is redadable and maintainable, what will be easy to learn for new people coming aboard the project? Are we optimizing for just the latest Apple machines, or do we want this stuff to be runnable on a ten year old ThinkPad? The questions may start out purely technical, but very soon the answers start to reflect an organization's values.
Sumu makes heavy use of SIMD already in its oscillator banks. But the 4x filter object is one that had to wait until after the initial release. Between this and other optimizations, Sumu 1.2 will use around 30% less CPU than 1.1.3. And there's more optimizing to come. My goal is to run it on this ten year old ThinkPad over here!
@rjschrei sorry to hear about your gear.
Thanks everyone! Sooooo much moss wants to grow on our roof here in the Pacific Northwest. I think I'm going to hire a professional.
Thanks for the additional info. If you can email me at support@madronalabs.com and send a crash log, it will help me figure this out.
Hey @intervolver I hear you are pretty frustrated with the sample import process, even without the crash. Obviously, you're not alone. I have plans to make it better.
As far as the crash, please contact me at support@madronalabs.com. I'm not getting any crashes with importing here, so maybe it's the specific files you are importing that can cause it. I'd like to get a hold of them and try to reproduce the problem.
Maybe it's overwriting the created .sumu files that is causing the crash? When you describe reimporting on your edit, one difference is that the files already exist. If you try deleting all the .sumu files in the folder you're writing to and importing again, you could test this. I'll do so as well.
It's a commonly asked question so I'm copying this info to a new thread in hopes it will be found more easily.
The Vutu app makes .utu files. These are a plain-text, editable, JSON format containing partials maps.
In Sumu, you can import the .utu files. The import process creates .sumu files, which are compressed to save space. The import also does some more analysis and saves it in the compressed file.
To import .utu files in Sumu, click the [...] in the Partials module. There's just one choice in this Popup menu: import partials. Then select a folder to import.
When you import a partials folder, it imports the whole directory tree underneath the one you pick, including any folders that contain .utu files.
So if I have on my disk
~/VutuFiles/Strings/cello.utu
~/VutuFiles/Strings/viol.utu
~/VutuFiles/Noises/tinkle.utu
~/VutuFiles/Noises/harsh/blender.utu
and then bring up the import dialog (partials/...) and select the folder ~/VutuFiles to import,
the files
~/Music/Madrona Labs/Sumu/Partials/Strings/cello.sumu
~/Music/Madrona Labs/Sumu/Partials/Strings/cello.sumu
~/Music/Madrona Labs/Sumu/Partials/Noises/tinkle.sumu
~/Music/Madrona Labs/Sumu/Partials/Noises/harsh/blender.sumu
will be created, along with the directories on the way.
Importing again will (for now) overwrite these files.
The intention is to "sync" your entire partials development folder at once. So if you make a folder somewhere called "VutuPartialsForSumu" or something, with everything you want to import into Sumu, and always select it when you import, you will keep your partials organized based on that folder's structure.
-Randy
Looks tasty!
These are already imported into .sumu format! So, you do the following:
- go to our Google drive
- click the "..." to download the whole theory folder
- put the theory folder in .../Madrona Labs/Sumu/Partials with all the other partials.
The "import partials" converts utu files into .sumu format. You do not need to do that here.