


Sumu is an additive instrument that I've had in the works for a long time. Now that it's nearing completion and heading towards a public beta soon I'm going to break with the way I normally do things and put some detailed info out ahead of its release.

Sumu is another semi-modular instrument. It shares the general appearance of its patcher-in-the-center design with Aalto, Kaivo and Virta. As you can see, it's on the more complex end of the spectrum like Kaivo. Everything is visible at once and there are no tabs or menu pages to navigate, which suits the way I like to program a synthesizer tweaking a little something here, a little something there.
In the same way that Kaivo brought two different and compatible kinds of synthesis together, combining granular synthesis with physical modeling, Sumu combines advanced additive synthesis with FM synthesis.
What's most different about Sumu compared to my other synths is that the signals in the patcher are not just one channel of data, but 64—one for each partial in a sound! By keeping all these channels of data independent and still using the same patching interface, Sumu offers a very usable entry point into additive synthesis, and a range of musical possibilities that have only been approachable with high-end or academic tools or just coding everything yourself... until now.
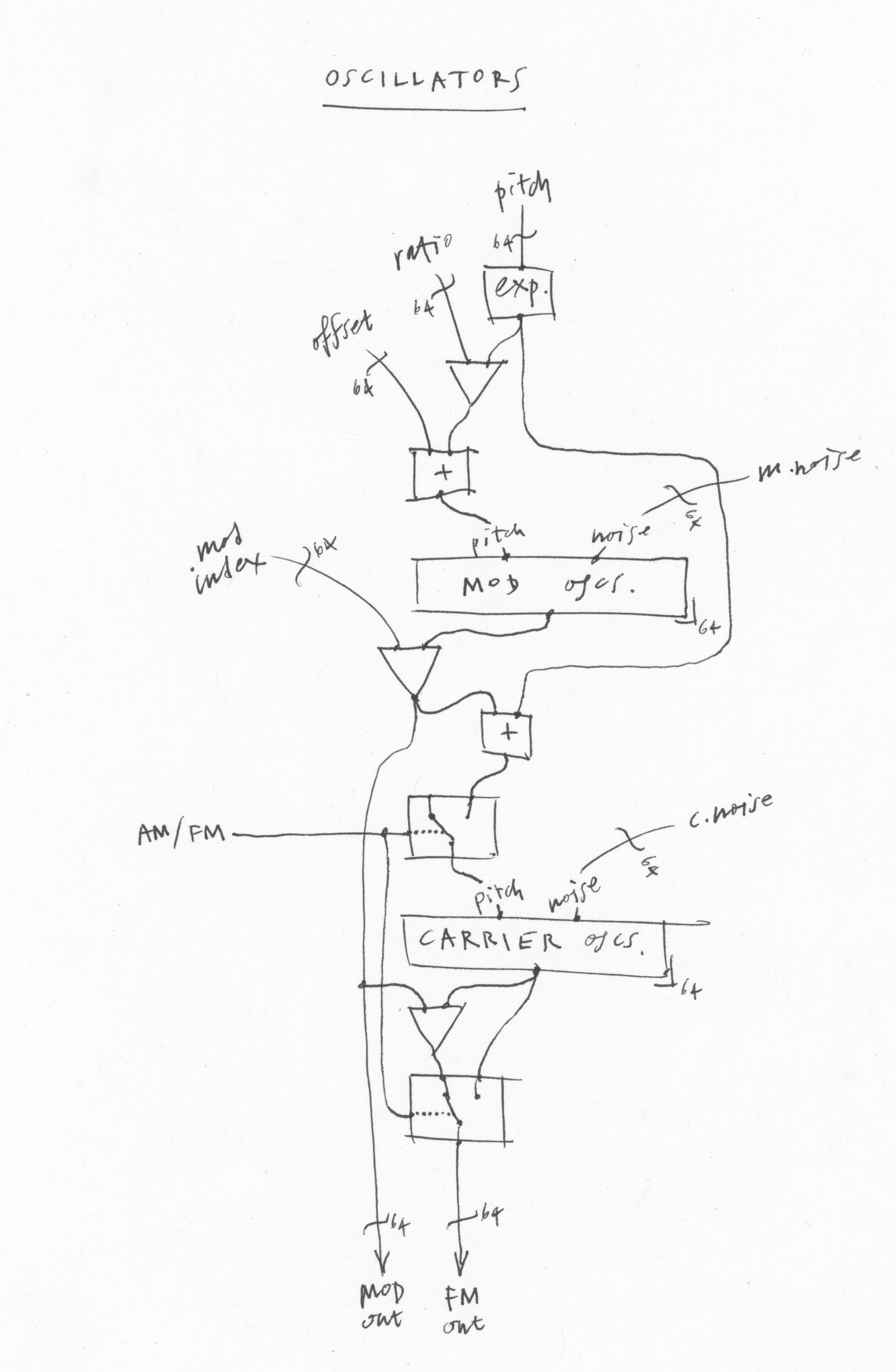
Each of Sumu's oscillators is the simplest possible kind of FM:a single carrier+modulator pair. And the modulator can produce a variable amount of noise, which like the modulation ratio and depth can be controlled individually per oscillator. In a single voice there are 64 such pairs. Obviously a lot of sounds are possible with this setup—in fact, with the right parameters varying appropriately we can reproduce any musical sound very faithfully with this kind of oscillator bank.
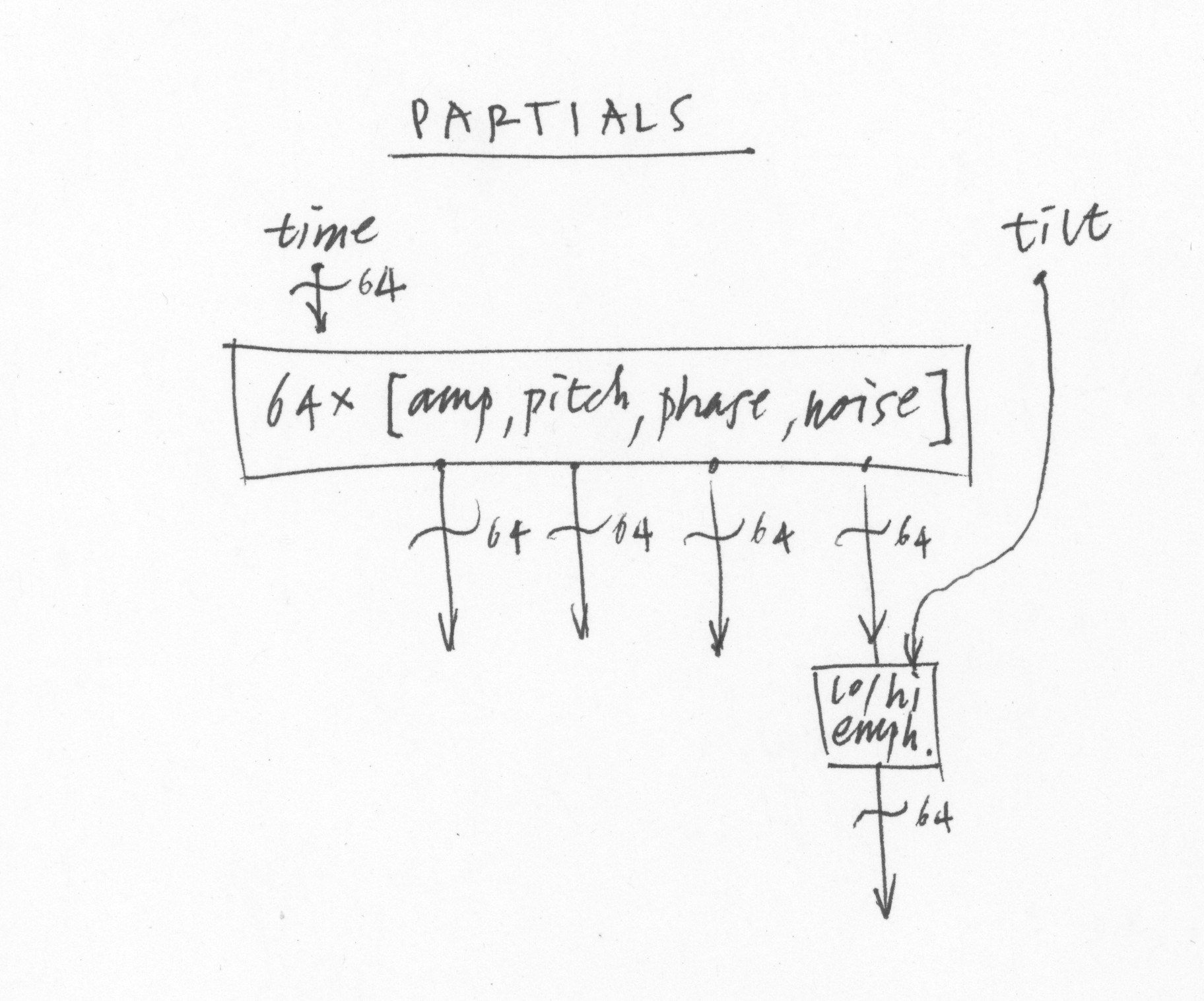
There are a few ways of generating all of those control channels without the kind of painful per-partial editing that some of the first digital synths used. The first is the PARTIALS module up top, where you can see a diagram of all the 64 partials over time. This is like a sonogram style of diagram where x is time, y is pitch, and thickness of each like is amplitude. There is also an additional axis for noisiness at each partial.
A separate application will use the open-source Loris work by Kelly Fitz and Lippold Haken to analyze sounds and create partial maps.
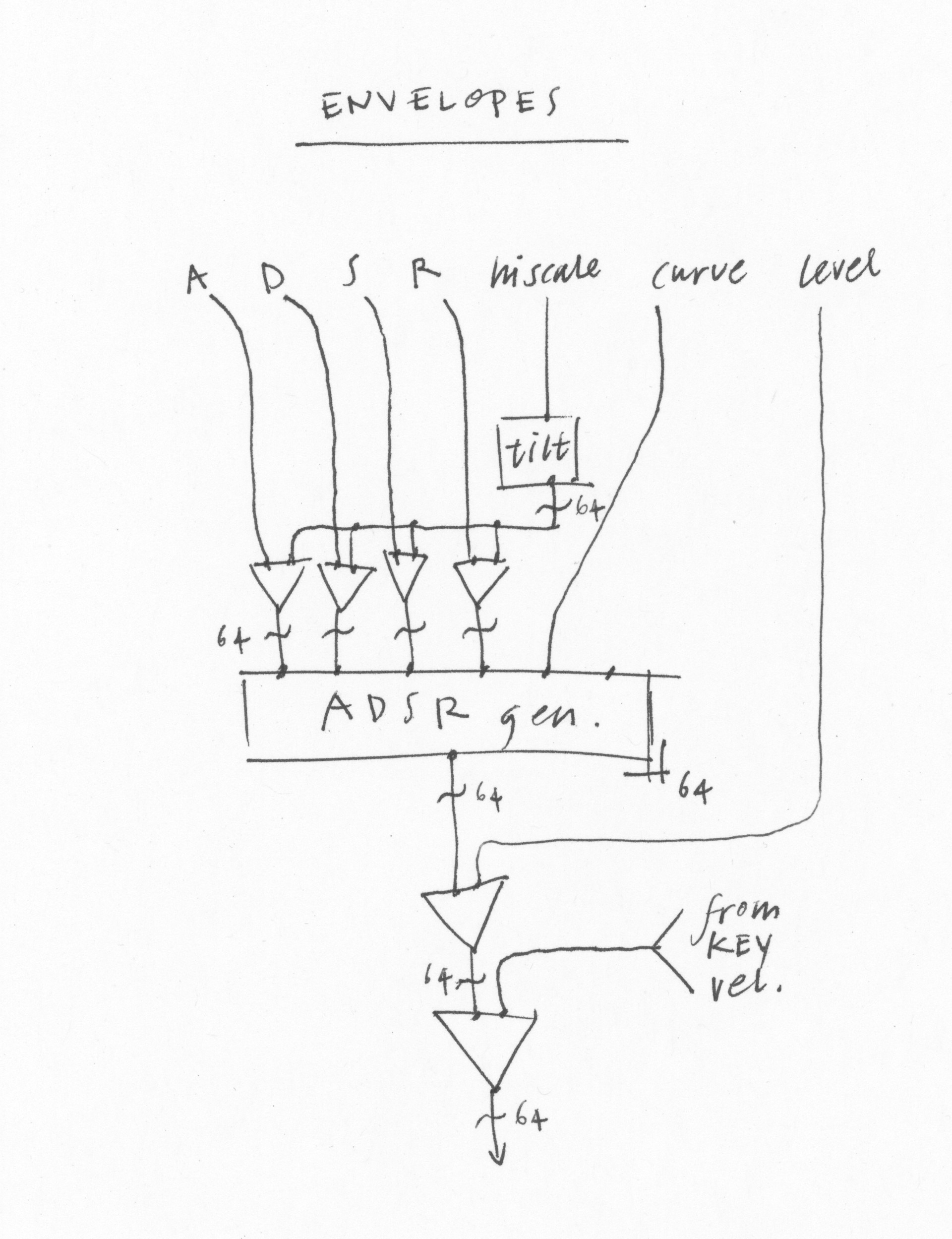
Another way of generating control data is with the ENVELOPES module. It’s a normal envelope generator more or less—except that it generates 64 separate envelopes, one for each partial. Generally you would trigger them all at the same time, but each does have its own trigger so they can be separate. Using the “hi scale” parameter the high envelopes will be quicker than the low ones, making a very natural kind of lowpass contour to the sound.
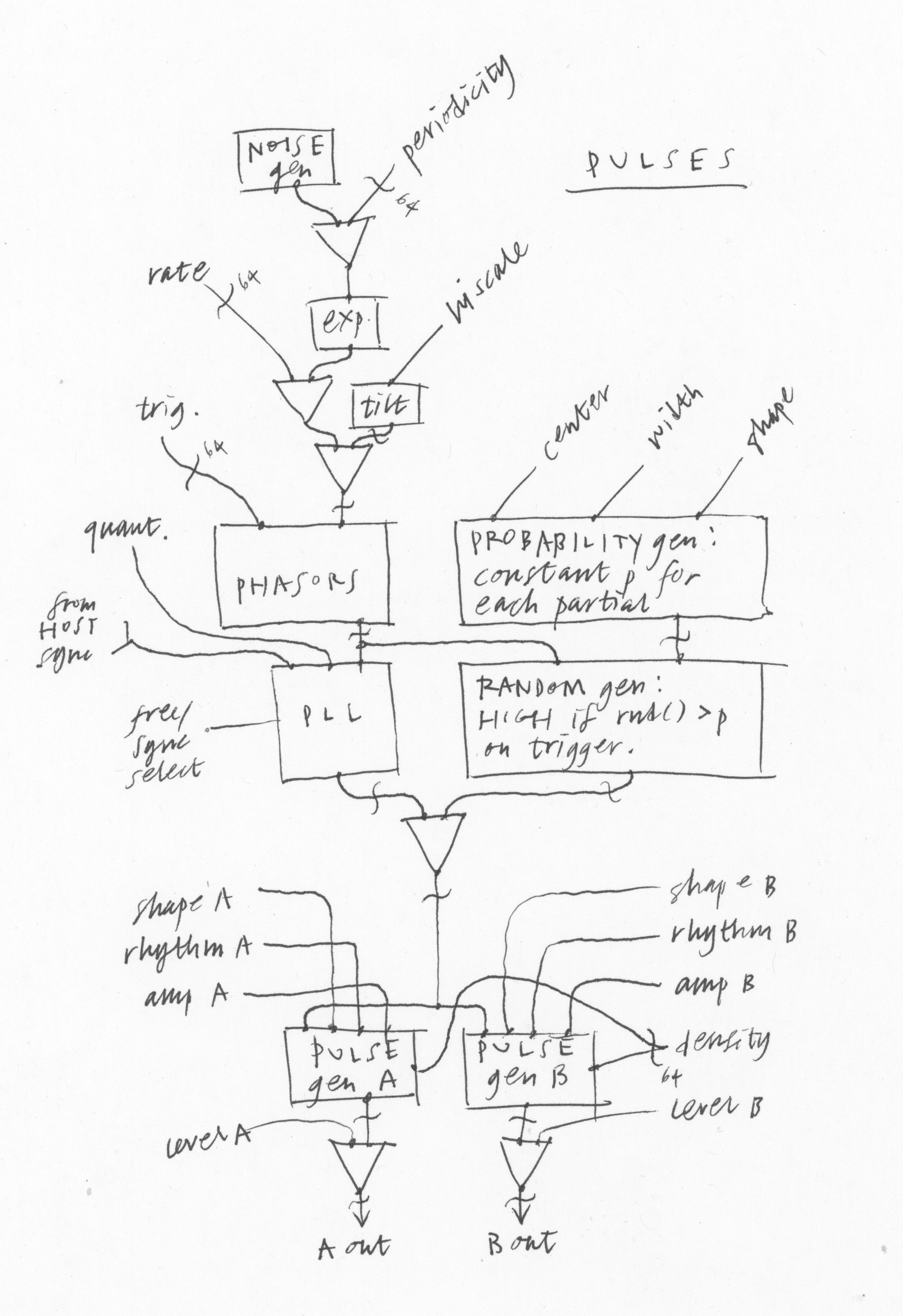
Finally on the top row there’s the PULSES module. This combines an LFO and a randomness generator into one module. The intensity and other parameters of the pulses can be different for every partial. So this makes modulations that can be focused on a certain frequency range, but you don’t have to mess around editing partials one by one. You could also, for example, use the pulses to trigger the envelopes all at different times.
The PULSES module was inspired by my walks in a small canyon near my house, and listening to the very finely detailed and spatially spread sounds of water running in a small creek. Each drop contributes something to the sounds and the interplay between the parts and the whole is endlessly intriguing.
To make a water drop sound, two envelopes are needed at the same time: a rise in pitch and an exponential decay in amplitude. So PULSES lets you put out two such envelopes in sync. Then of course we generalize for a wider range of functions, so we can find out, what if the drops were quantized, or had different shapes over time? A voice turning into a running river is the kind of scene that additive synthesis can paint very sensitively. The PULSES module is designed to help create sounds like this.
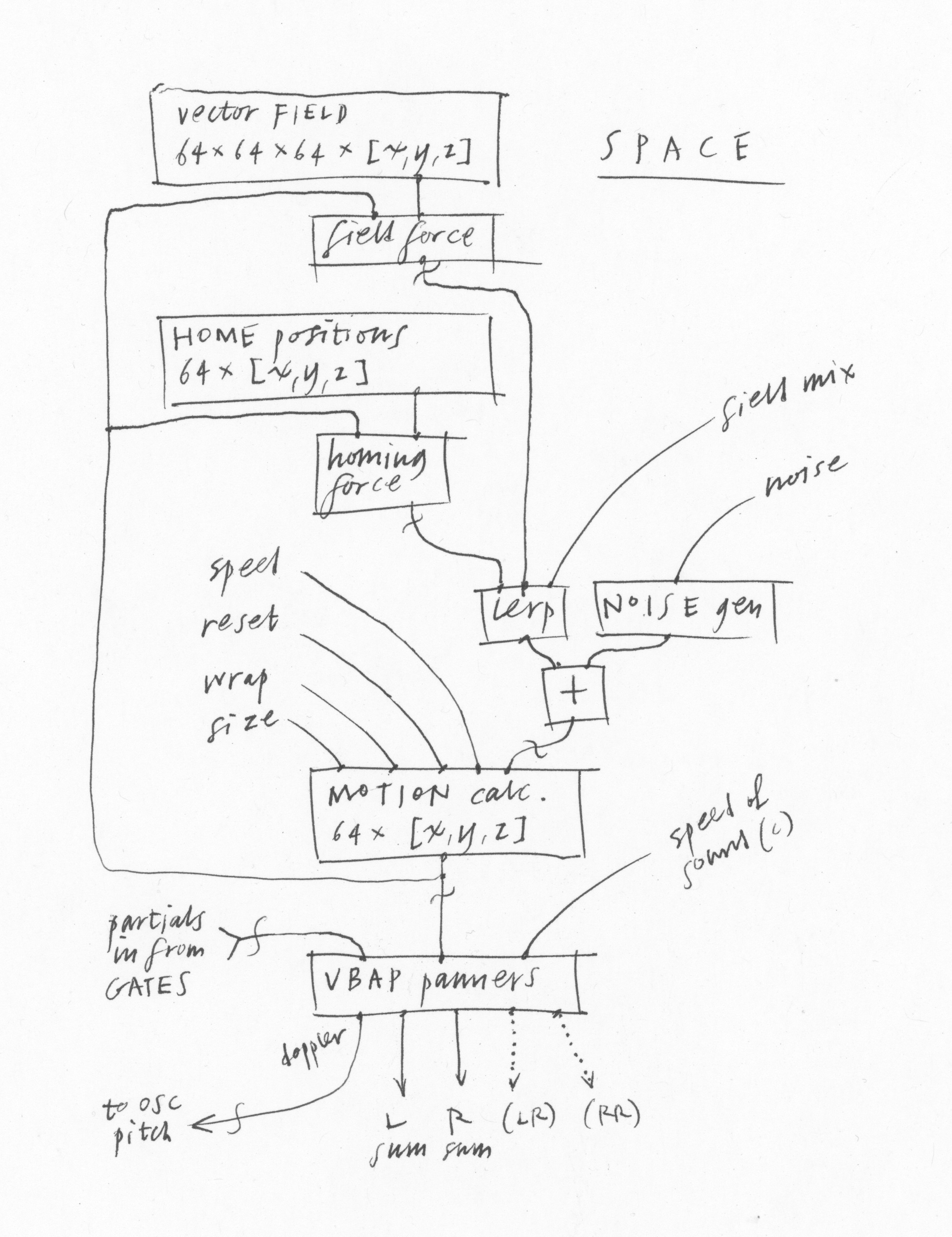
The SPACE module lets us position each partial in the sound independently. Coming back to the creek idea, we can hear that certain pitch ranges happen in certain locations around us due to the water speed and the resonances of different cavities. This all paints a lively acoustic scene. By positioning many little drops independently, while allowing some variation, we can approximate this kind of liveliness.
This module centers around two kinds of data, a set of positions for each partial known as home, and a vector field: a direction [x, y, z] defined at each point in a 3-dimensional space. There will be a set of both the home and the field patterns to choose from. By offering these choices, and a small set of parameters controlling the motion of the partials, such as speed, the homing tendency, and the strength of the vector field, we can quickly create a wide variety of different sonic spaces without the tedium of editing each partial independently.
The RESONATORS module is very simple and inspired by the section of the Polymoog synthesizer with the same name. It’s simply three state-variable filters in parallel, with limited bandwidth and a bit of distortion for that “warm” sound. In Sumu, a synth we could otherwise describe as “very digital,” it’s nice to have a built-in way of adding a different flavor.
So I have this interface you see above, and a sound engine, and I'm working feverishly to marry the two. To enable all of the animations and the new pop-up menu, I wrote a whole new software layer that provides a completely GPU-based UI kit and interfaces directly with the VST3 library. Because it's been such a long process this time, I'm going to "build in public" more than I am used to doing, and have a public beta period. My plan is for this to start in December. Meanwhile I hope this information gives you interested folks something to whet your appetites, and even a basis for starting to think about what kinds of patches you might want to make.

i would also like one last link to download the beta
please email me and I'll send you one.
oh!! thank you! I've sent an email.

Hello Randy,
I send you an email asking for a link to be able to download the beta ... no news ?
Thanks anyway
Warm regards
Serge
Sorry for the delay in replying. I've been so deep in the coding. Because I'm very busy finishing up and the actual release is quite close now, I've stopped adding people to the beta list so I can focus better. Thanks for your understanding.

So looking forward to this Randy - cannot wait!

Hello, Randy! I will be very glad to try this incredible synth Sumu.
Looks very Interesting

I just came across this on YouTube. Prepare to get excited by Sumu's possibilities. I just scratched the surface of this video, but based on my brief listen (I'm planning on listening in its entirity later) there's loads of potential here. https://youtu.be/DC-6txYlCcA

Hi Randy! Any idea when this will come out? Will it support mpe?
We're working hard to ship this month. There will be an Early Access version first, then 1.0 with MPE support. Lots more info on Early Access soon.

Really interested in this, but some of the patches on the Early Access version for Windows are absolutely crippling to my CPU. I've never seen a "349%" (!) reading show up without ever playing a note, and nothing comes in under 60% at present!
I don't know whether further optimization remains to be done --I dearly hope so--but on a 16GB RAM Windows multicore system, this currently looks to be a non-starter. (Yes, I know, I need to upgrade --but it's never been this bad--this makes even Generate look like a walk in the park! Any plans to integrate multi-core swapping on the finished version?)
Like our other synths, each patch in Sumu has a fixed number of free-running voices set in the INPUT module. Because all of our synths can make notes by turning dials, just like modulars, whether you play a note or not, that max number of voices is always taking up CPU.
So for those few patches that were set at 16 voices because they sounded too cool to resist that way, you can turn the number of voices down to 4 or something.
And yes, it's truly still a CPU-heavy synth. Like our other ones it will get much better over time as I optimize.

I was checking my email while still in bed, right after waking up, when the news of Sumu being released reached me (I'm in CET) and I had it installed before I even brushed my teeth. It took me like 3 minutes of testing to get the license. It's exactly what I hoped for, and I can finally start making music!:)
Thank you for all the synths (and madronalib)!